
How to Use IndexedDB to Handle 3D WebGL Assets
In this article, I’d like to share everything I’ve been learning while developing the support for IndexedDB inside our 3D WebGL Babylon.JS game engine. Indeed, since 1.4.x, we’re now supporting storing & loading the JSON scenes containing our 3d meshes and their .PNG or .JPG textures as blobs from IndexedDB.
This article is built around my own experience on this topic. It’s based on the way I’ve solved the various issues I have encountered while working with IDB. You’ll then find some explanations & tips on what you must pay attention to when you’ll work with IndexedDB. I will also share how and why we’re using it inside our 3d WebGL engine. Still, this article may be helpful for anybody looking at IndexedDB in general. 3d gaming will just serve as an illustration of its usage.

- Introduction to IndexedDB
- Why using IndexedDB in our gaming scenarios?
- Understanding the execution workflow of IndexedDB & handling exceptions
- Some tips I’ve learned & used during the development process
- How we’re using it inside Babylon.JS
Introduction to IndexedDB
IndexedDB is a non-relational database using a keys/values mechanism. It’s a noSQL DB. You could see it as the third generation of storage handled by the browser. The first one was the cookies, the second one was the local storage.
It’s a W3C specification, currently in Candidate Recommendation. It’s implemented by the majority of modern browsers: IE10+, Chrome/Opera & Firefox. Even better, the specification is supported in the un-prefixed version since IE10, Firefox 16 & Chrome 24/Opera 15. Looks like it’s ready for production usage! That’s why we’re using it on our website today: http://www.babylonjs.com
I won’t cover the basics of IndexedDB as there are good resources on the web for that. However, I’ve spent a lot of time identifying up-to-date documentations and well explained tutorials. Indeed, as the specification has evolved for several years, most of the articles you’ll find on the web will be deprecated.
If you’d like to avoid losing time on these deprecated contents, here are my 4 recommended articles to read:
1 – The W3C specification itself: http://www.w3.org/TR/IndexedDB/ . It really contains everything and it’s relatively easy to read. I’ve frequently ended up reading the spec to really understand how it works to solve some of my issues. Sometime, we just forget that the W3C spec could be the best documentation. ;-)
2 – Working With IndexedDB by Raymon Camden. This one is very recent, very well explained & perfect for a beginner. My article will probably be complementary to this one as I’ll be storing images as blob not covered by this article.
3 – IndexedDB on our MSDN. It contains some interesting details and a big tutorial.
4 – Using IndexedDB on MDN. Good documentation as always on MDN.
So please read at least the 2nd link if you don’t know anything about IndexedDB yet.
After that, based on my experience, let me share the biggest warning you should have in mind: really understand that IndexedDB is fully asynchronous and transaction based. You need to wait for the asynchronous read/write operations to finish and you need also to wait for the asynchronous transactions to complete before being sure that everything is ok in your code. I will illustrate that with some little diagrams below.
Why using IndexedDB in our gaming scenarios?
I’ve started thinking about using IndexedDB during my summer vacation. I was at home with my incredible 2MB ADSL line and I was depressed each time I needed to reload a scene from our website. Some of the scenes could take more than 5 minutes to load. I was then wondering to myself: “As I have already downloaded all the assets once, why should I re-download them?â€
You may argue that this is the job of the browser’s cache. That’s right. Most the time, the browser will do the job perfectly. But there are conditions where the cache will be invalidated or deleted: quota for the cache has been reached, user is deleting his web content cache or simply because of the heuristic used by the browser. Your game’s content could then suffer from that as it will live by default with all the other content downloaded from the web.
I wanted something better for a gaming experience. As a gamer, I’m ok to download the assets during the first launch of the game. But I don’t want to lose time re-downloading because my browser decided to clean some of its cache. When I’m playing a game, I want to play it immediately. By isolating the data of the game into IndexedDB, we have less chance to fall into the various cache cleaning scenarios. We’re then gaining greater independency.
Moreover, we’ve recentely ship an incremental loader in BabylonJS. This means that the scene will load almost immediately and we will load the resources on demand based on where the camera is currently looking at. The slight problem with this approach is that the resources (meshes geometries & textures) will be downloaded first from the web server and injected into the 3d engine. We will suffer from the latency of the network. The incremental geometry will not be displayed immediately and will appear suddenly a couple of seconds after the gamer will have moved the camera. Using our IndexedDB approach, we can preload the resources in the DB in background and load them almost instantly via the incremental loader. We will then remove the network latency problem. This is still something we need to work on but we now have all the pieces to build it in a future version.
At last, being able to store the assets in IndexedDB enables the offline scenario. You can now imagine a game loading from the web and working perfectly fine without any connection after that! You just need to combine HTML5 Application Cache APIs with IndexedDB.
To illustrate that, click on the image below to navigate to an online demo:
Load the “Heart†scene, press the back button and then load the “Omega Crusher†scene. By doing that, you will save both scenes in IndexedDB. Now, try to switch off your network adapter to go offline. You should be able to navigate to the home page and launch both scenes even without any network connection at all!
I will explain how to build such a demo in the last part of this article.
Understanding the execution workflow of IndexedDB & handling exceptions
First of all, please note that all the code I’ve written for Babylon.JS is available on GitHub here: babylon.database.js . Feel free to have a look to better understand the below explanations.
Moreover, my first advice would be: register yourself to all possible events described by the W3C spec and put some simple console.log() inside them during the development process to understand the execution pipeline.
Opening the database
Let’s start by reviewing what will/could occur when you will open the Indexed Database.
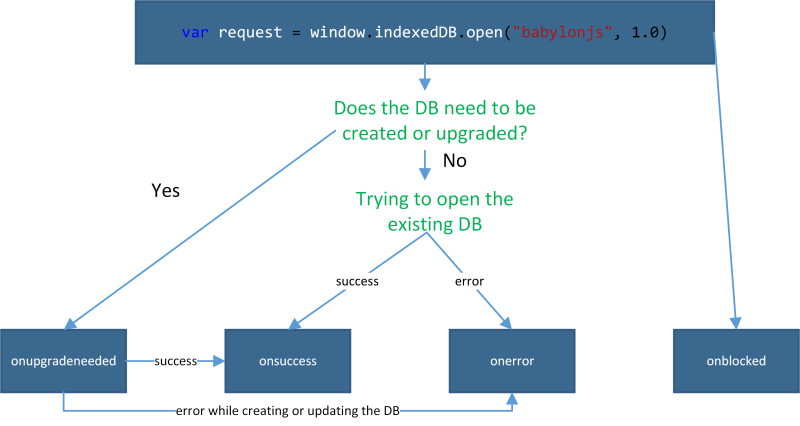
The first mistake I did was to think that the onupgradeneeded event wasn’t followed by the onsuccess event. I was believing that onsuccess was only raised if the DB already existed and opened successfully. Thus, I was putting my success callback in both events handlers. It was then logically triggered twice but I was expecting it to be triggered only once. In conclusion, call your final callback function only inside the onsuccess event handler.
Moreover, you could go from onupgradeneeded to onerror if the user has refused access to the DB when being prompted. For instance, here is the request being displayed in Internet Explorer:

If the user clicks “not for this siteâ€, you’ll fall in your onerror handler.
You can check my code by reading the BABYLON.Database.prototype.openAsync() function on GitHub.
Handling image blob storage in all browsers
To better understand this part, you can check my code contained in the BABYLON.Database.prototype._saveImageIntoDBAsync() function on GitHub.
Please also have a look to this article: Storing images and files in IndexedDB by Robert Nyman. It’s a bit outdated but it’s well explaining how to store images in IDB as a blob type.
The global concept of my function is to store the textures of our 3d meshes inside IndexedDB. For that, I’m first downloading them using XHR2 and requesting the response type to be a blob. I’m then basically using the same approach as the above article.
However, while testing this approach, I’ve discovered that IE10+ and Firefox were well supporting storing images as blob in IndexedDB but not Chrome yet. Chrome is raising a DataCloneError if you tries to save a blob structure in its DB.
To cover Chrome specific case without doing UA sniffing (which is bad!), I’m protecting the saving operation. If it’s failing with an error code 25, I know that the UA is not supporting storing blob. As I’ve already downloaded the data via the XHR, I’m simply filling the HTML image element with a createObjectURL. But for future calls, I’m then setting the flag isUASupportingBlobStorage to false to indicate that caching images in IDB is not available for this browser.
I was thinking about better covering the Chrome case by using some existing polyfills that uses the FileSystem APIs or by encoding the images in base64 for storage. I’ve then found this stackoverflow thread discussing about the same problem: Storing Image Data for offline web application (client-side storage database) . But as a bug is currently opened to implement that in a future version of Chrome: Issue 108012: IndexedDB should support storing File/Blob objects and it seems it will be soon shipped, I’ve decided to let Chrome falling back to its default image caching system.
At last, you’ll notice that in a general manner, in case of an error (XHR error or whatever), I’m using the classical way to load an image by using the HTML image element and its src property. In this way, I’m maximizing the chance to load our textures whatever occurs during the saving process.
Handling Quota reached
This one deserves a little schema to understand what’s going on! It will confirm you why it’s important to understand that IndexedDB is transaction based.
First, let’s talk about the default quota in place in the browser. By default, IE10+ allows you to store 10 MB before requesting the user to exceed this limit. You can change this value in the options. Then, it has a final maximum limit of 250 MB per domain and you can’t change this value. So, we have here 2 possible cases to reach the quota and we need to handle that in our code.
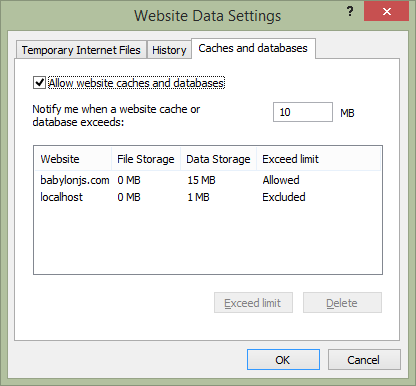
Firefox will warn you when you will reach the 50 MB first quota limit then it doesn’t have a maximum quota. For Chrome, the answer is less simple but you can find its way to handle quotas here: https://developers.google.com/chrome/whitepapers/storage#temporary
Now, to understand how to properly handle the quota, let’s review a simple case. If you’re navigating to our website: http://www.babylonjs.com, you’ll notice there are several scenes available to test. One of them is named FLAT 2009.

This scene has a JSON file named Flat2009.babylon of 29 MB. The scene file is of course the first file being downloaded by the engine. It’s then possible that the first time you will navigate to our website, you will try this scene first. What will exactly occur?
It will load the JSON scene via an XHR request and try to save it into IndexedDB. Let’s take IE11 as the browser. As it has a default first warning limit of 10 MB, this limit will be already reached by only downloading this unique scene. My first guess was that the write request operation should fail as 29 MB > 10 MB. Well, this is not exactly what’s going on. To better understand, please review the below diagram:
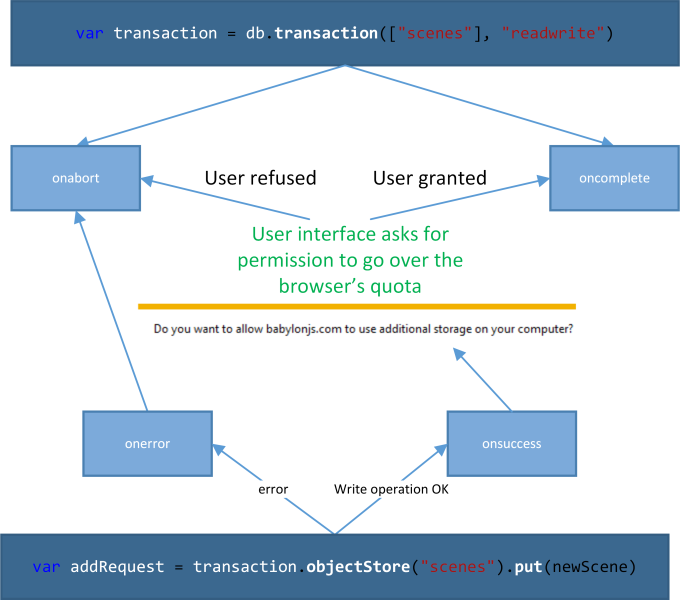
The first line of code is creating the transaction. From this transaction, we’re launching the write request to put the new freshly downloaded scene into the “scenes†store. In fact, the request named “addRequest†will first succeed. Indeed, logically, your browser should be able to write the 29 MB of the scene into the DB. But as the quota is reached, the browser will then prompt the user to ask him if he’s allowing the browser to exceed the default quota. If the user refuses, the transaction will be aborted and the file will be removed from the DB.
Again, the conclusion is the same as before. Your final success handler must be called from the oncomplete handler of the transaction and not from the onsuccess handler of the request.
You can review this logic by reading code of BABYLON.Database.prototype._saveSceneIntoDBAsync() on GitHub. The most important part is here:
// Open a transaction to the database var transaction = that.db.transaction(["scenes"], "readwrite"); // the transaction could abort because of a QuotaExceededError error transaction.onabort = function (event) { try { if (event.srcElement.error.name === "QuotaExceededError") { that.hasReachedQuota = true; } } catch (ex) { } callback(sceneText); ; transaction.oncomplete = function (event) { callback(sceneText); ;
You need to test the “QuotaExceededError†to be sure the transaction has been aborted because of the quota. In my case, I’m setting a flag hasReachedQuota as there’s no need to try further write operations in the DB, this won’t work anymore.
Some tips I’ve learned & used during the development process
Let me share here some tips I’ve been using during the development process that could be useful to you also.
How to clean/remove Indexed Databases in the various browsers
You will probably need to remove the DB created during your tests to restart from zero.
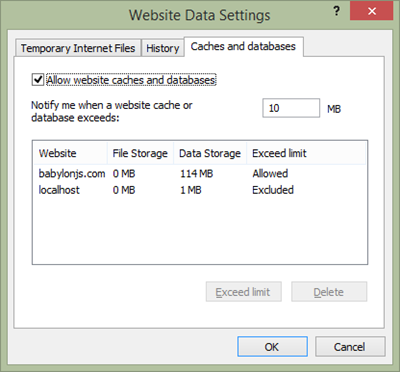
Internet Explorer
Go to “Internet Options†–> “Settings†–> “Caches and databases†and select the domain you’d like to delete.
Chrome
Navigate to chrome://settings and go to “advanced settingsâ€. Click on “Clear browsing data…†button. Finally, click on the “Clear browsing data†button in the following form:
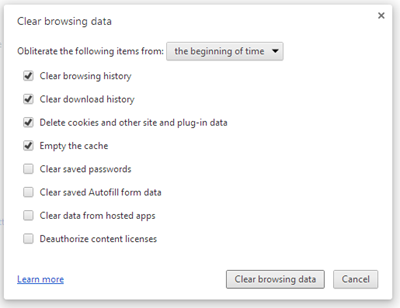
Or you can delete the folder associated to your domain name directly here: %AppData%\Local\Google\Chrome\User Data\Default\IndexedDB
Firefox
You need to go into this folder: %AppData%\Roaming\Mozilla\Firefox\Profiles\your profile id\indexedDB and delete the folder associated to your domain name.
Did you know about InPrivate/Incognito browsing?
If you’re browsing your website using the InPrivate or Incognito mode of the browser, IndexedDB will be disabled (like localStorage & cookies by the way). window.indexedDB will be undefined. This could be useful to do some tests with/without IndexedDB. For instance, it was useful for me to test a browser having WebGL supported without IndexedDB enabled.
How to check resources are really loaded from the DB
During my tests, I was always wondering if my database logic was working fine and if the resources were really loaded from my DB rather than directly from the web. I’ve found a very easy to way to check that: using the F12 development bar of IE11. Test it by yourself:
– using IE11, navigate to http://www.babylonjs.com
– press F12 and select the “Network†panel, press the “Always refresh from server†button. We’re now asking the browser to bypass his cache and always try to download the assets from the webserver. Now press the “Play†button to start capturing:
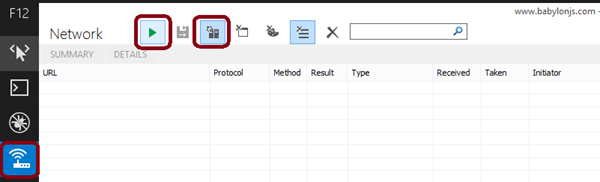
– try to load the “Heart†scene. The first time, you should see a trace like this one:
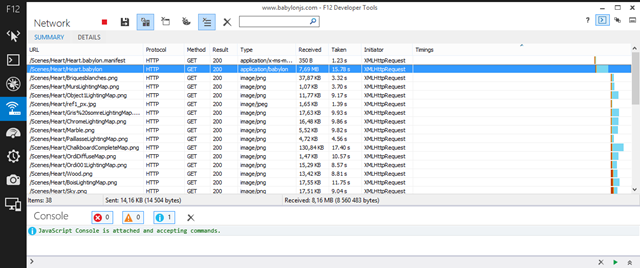
38 items are downloaded using XHR requests.
– go back to the home page and reload the very same scene. You should see now only 1 HTTP request getting out:

A unique XHR request is sent to check the manifest file. We’re now sure that everything else is coming from our local IndexedDB.
Some internal details on IE, Firefox & Chrome
Last tip: I’ve found this article by Aaron Powell very interesting to read: How the browsers store IndexedDB data . You’ll learn that IE is using ESE (Extensible Storage Engine) to implement IndexedDB, Firefox is using SQLite & Chrome is using LevelDB.
It’s also in the same article where I’ve learned where the DBs of Firefox & Chrome are hidden.
How we’re using it inside Babylon.JS
Our main objective was to keep it very simple to use in our gaming engine and to affect as less as possible the rest of the code. My mission was then to inject my logic inside the 2 loading functions that load the textures and the JSON scene file.
If you’d like to know how to enable the support for IndexedDB with Babylon.JS, start by simply reading the tutorial I’ve written on our wiki: https://github.com/BabylonJS/Babylon.js/wiki/Caching-the-resources-in-IndexedDB
The usage is then very simple. Add a .manifest file to your .babylon scene and indicate the version number of your assets and if you’d like to cache the scene, the textures or both.
I’ve done a ton of unit tests to be sure that my code was covering all possible cases. Indeed, as I’m the first to be called to handle the assets, if my code fails, nothing will be displayed or rendered. Handling I/O has always been a critical part.
Most of the scenes are configured to use offline for the scene and their textures on our website: www.babylonjs.com . For instance, you can try the “Heart†scene. The scene is described into heart.babylon and the associated manifest file is then heart.babylon.manifest. One of the scenes is configured to only cache the texture. It’s the “The Car†scene. It’s because the JSON file, TheCar.babylon, is more than 93 MB. IE11 and Chrome can’t store files sized like that into their DB. I’ve then decided to avoid trying to cache it.
At last, to build a fully offline functional demo using Babylon.JS like this one: Babylon.JS offline demo, you need to couple our database logic to the HTML5 Application Cache API. I’ve already covered its usage for a 2d canvas game here: Modernizing your HTML5 Canvas games Part 2: Offline API, Drag’n’drop & File API
The approach is strictly the same for a 3d WebGL game. In this case, I’ve put inside the HTML5 manifest file the minified version of Babylon.JS plus a couple of images used on the home page. More important: I’ve included the .babylon.manifest files inside it also. I’ve finally obtaining this simple small cache manifest file named babylon.cache:
CACHE MANIFEST
Version 1.1
CACHE:
abylon.js
and.minified-1.1.1.js
ndex.html
ndex.css
ndex.js
creenshots/heart.jpg
creenshots/omegacrusher.jpg
ssets/BandeauEmbleme.png
ssets/Bandeauhaut.png
ssets/BtnAbout.png
ssets/BtnDownload.png
ssets/gradient.png
ssets/Logo.png
ssets/SpotDown.png
ssets/SpotLast.png
cenes/Heart/Heart.babylon.manifest
cenes/SpaceDek/SpaceDek.babylon.manifest
NETWORK:
Indeed, if you don’t put the .babylon.manifest files into the cache manifest, a 404 error will be raised when the engine will try to check for their values. And by default, Babylon.JS assumes that this means you want to download the assets from the web.
To conclude, thanks to our approach, now imagine that this Babylon.JS offline demo represents the main menu of your 3d game and that’s each scene is a specific level of your game. If you’d like to only update one of the level, you just need to change the version included in its associated .babylon.manifest file. Our 3d gaming engine will then only update this specific level in the database. This is something you can’t do by only using the HTML5 Application Cache API. With AppCache, there is no delta updates. You’re forced to re-download everything specified in the cache manifest file. This would mean that updating one of the levels of your game would imply to reinstall completely the game from the web into the HTML5 cache.
I hope that our approach and tips will inspire some of you to make nice usage of IndexedDB on the web! Feel free to share your feedbacks in the comments.


