
How to Write a 3D Soft Engine from Scratch – Part IV B
In the previous tutorial, learning how to write a 3D software engine in C#, TS or JS – Rasterization & Z-Buffering, we’ve learned how to fill our triangles. As we’re CPU based with our 3D software engine, it really starts to cost a lot of CPU time. The good news is that today’s CPUs are multi-cores. We could then imagine using parallelism to boost the performance. We’re going to do that in C# only and I’ll explain why we won’t do it in HTML5. We’re also going to see some simple tips that could boost the performance in such rendering loop code. Indeed, we’re going to move from 5 FPS to 50 FPS, a 10X performance boost!
This tutorial is part of the following series:
1 – Writing the core logic for camera, mesh & device object
2 – Drawing lines and triangles to obtain a wireframe rendering
3 – Loading meshes exported from Blender in a JSON format
4 – Filling the triangle with rasterization and using a Z-Buffer
4b – Bonus: using tips & parallelism to boost the performance
5 – Handling light with Flat Shading & Gouraud Shading
6 – Applying textures, back-face culling and WebGL
In this tutorial, you will learn how to draw lines, what a face is and how cool is the Bresenham algorithm to draw some triangles.
Compute the FPS
First step is to compute the FPS to be able to check if we’re going to gain some performance by modifying our algorithm. You can do that either in C# or TypeScript/JavaScript of course.
We need to know the delta time between two frames rendered. We then simply need to capture the current time, draw a new frame (requestAnimationFrame in HTML5 or CompositionTarget.Rendering in XAML), capture again the current time and compare it to the previous time saved. You will have a result in milliseconds. To obtain, the FPS, simply divide 1000 by this result. For instance if it’s 16,66 ms, the optimal delta time, you will have 60 FPS.
You can do that after each frame rendered to have a very precise FPS or compute the average FPS on 60 samples for instance. David and I already worked on this topic through this series: Benchmarking a HTML5 game: HTML5 Potatoes Gaming Bench
In conclusion, in C#, add a new TextBlock XAML control, named it “fps†and use this code to compute the FPS:
DateTime previousDate; void CompositionTarget_Rendering(object sender, object e) // Fps var now = DateTime.Now; var currentFps = 1000.0 / (now - previousDate).TotalMilliseconds; previousDate = now; fps.Text = string.Format("{0:0.00} fps", currentFps); // Rendering loop device.Clear(0, 0, 0, 255); foreach (var mesh in meshes) { mesh.Rotation = new Vector3(mesh.Rotation.X, mesh.Rotation.Y + 0.01f, mesh.Rotation.Z); device.Render(mera, mesh); } device.Present();
Using this code, using the native resolution of my Lenovo Carbon X1 Touch (1600×900), I’m running an average of 5 FPS with the C# solution shared in the previous article. My Lenovo embeds an Intel Core i7-3667U with a HD4000 GPU. It’s a hyper-threaded dual-core CPU. It then shows 4 logical CPUs.
Optimization & Parallelization strategies
WinRT applications are using the .NET Framework 4.5 which includes the Task Parallel Library by default (TPL). If you pay attention in the way you’re writing your algorithm and if your algorithm can be parallelized, making it parallel becomes very easy thanks to TPL. If you don’t know this concept yet, have a look to Parallel Programming in .NET Framework 4: Getting Started
Avoid touching UI controls
The first rule for multi-threading/multi-tasking is to have 0 code touching the UI in the threads spawn. Only the UI thread can touch/manipulate graphic controls. In our case, we had piece of code accessing to bmp.PixelWidth or bmp.PixelHeight where bmp is of type WriteableBitmap. WriteableBitmap is considered as a UI element and is not thread-safe. That’s why, we first need to change these blocks of code to make them “parallelizableâ€. In the previous tutorial, we started by doing so. You simply need to save those values at the beginning. We’ve done that in renderWidth and renderHeight. Use these values in your code instead of accessing to bmp. Change all references to bmp.PixelWidth to renderWidth and to bmp.PixelHeight to renderHeight.
By the way, this rule is not only important for parallelization. It’s also for performance optimization in general. Thus, by simply removing accesses to the WriteableBitmap properties in my code, I’m switching from an average of 5 FPS to more than 45 FPS on the same machine!
The same rule is very important (even maybe more) in HTML5. You should absolutely avoid to test DOM elements properties directly. DOM operations are very slow. So it’s really not a good idea to access them every 16ms if it’s not necessary. Always cache the values you need to test later on. We’ve already done so in the previous tutorials for the HTML5 version of the 3D engine.
Be self-sufficient
A second rule is that the block of code that will be launched on the several available cores need to be self-sufficient. Your code doesn’t have to wait too long for the result of other block of code to continue otherwise it will lower the interest of parallelism. In our case, you’re lucky as I’ve managed to give you the code in previous tutorials to already respect this rule.
You may have seen that we have several areas where we could switch our classical For loop by a Parallel.For loop.
The first case is in the DrawTriangle method. We’re then going to draw several lines on a triangle in parallel. You can then easily convert the 2 normal For loop by 2 Parallel.For loop:
if (dP1P2 > dP1P3) Parallel.For((int)p1.Y, (int)p3.Y + 1, y => { if (y < p2.Y) { ProcessScanLine(y, p1, p3, p1, p2, color); } else { ProcessScanLine(y, p1, p3, p2, p3, color); } }); else { Parallel.For((int)p1.Y, (int)p3.Y + 1, y => { if (y < p2.Y) { ProcessScanLine(y, p1, p2, p1, p3, color); } else { ProcessScanLine(y, p2, p3, p1, p3, color); } });
But in my case, the output is a bit surprising. I’m lowering the performance switching back from 45 FPS to 40 FPS! So what could be the reason of this performance drawback?
Well, in this case, drawing several lines in parallel is not feeding the cores enough. We’re then spending more time in context switching and moving from one core to another than doing some real processing. You can check that with the embedded profiling tools of Visual Studio 2012 : Concurrency Visualizer for Visual Studio 2012
Here is the Cores utilization map with this first parallelization approach:
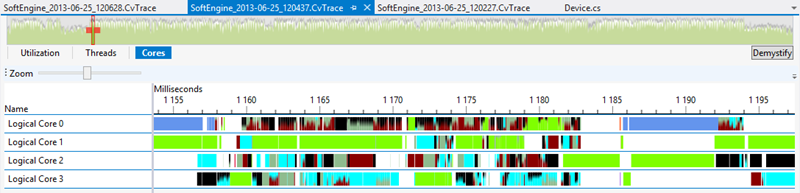
The various colors are associated to worker threads. It’s really non-efficient. Look at the difference with the non-parallelized version:
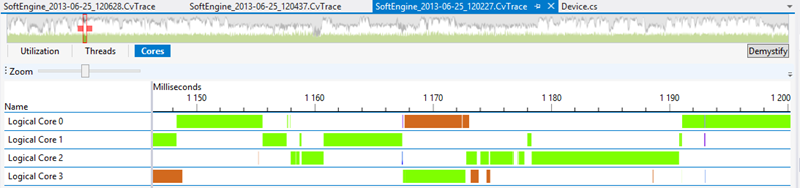
We’re only have 1 thread working (the green one) which is dispatched on the several cores by the OS itself. Even if we’re not using the multi-cores capabilities of the CPU in this case, we’re finally more efficient globally. We’re generating too much switching in our first parallelization approach.
Protect with lock and choose the right loop to parallelize
Well, I guess you came to the same conclusion than I. Parallelizing the loops in the drawTriangle method doesn’t seem to be a good option. We need to find something that will take more time to execute and will be more efficient in the cores switching. Rather than drawing a triangle in parallel, we’re going to draw several triangles in parallel. In conclusion, each core will handle the drawing of a complete triangle.
The problem by using this approach lives in the PutPixel method. Now that we want to draw several faces in parallel, we may fall into cases where 2 cores/threads will try to access the same pixel in concurrency. We then need to protect access to a pixel before working on it. We need also to find an efficient way to lock access to the pixels buffers. Indeed, if we’re spending more time protecting the data than working on it, the parallelization will be once more useless.
The solution is to use an array containing fake objects we will lock on.
private object[] lockBuffer; public Device(WriteableBitmap bmp) this.bmp = bmp; renderWidth = bmp.PixelWidth; renderHeight = bmp.PixelHeight; // the back buffer size is equal to the number of pixels to draw // on screen (width*height) * 4 (R,G,B & Alpha values). backBuffer = new byte[renderWidth * renderHeight * 4]; depthBuffer = new float[renderWidth * renderHeight]; lockBuffer = new object[renderWidth * renderHeight]; for (var i = 0; i < lockBuffer.Length; i++) { lockBuffer[i] = new object(); } // Called to put a pixel on screen at a specific X,Y coordinates public void PutPixel(int x, int y, float z, Color4 color) // As we have a 1-D Array for our back buffer // we need to know the equivalent cell in 1-D based // on the 2D coordinates on screen var index = (x + y * renderWidth); var index4 = index * 4; // Protecting our buffer against threads concurrencies lock (lockBuffer[index]) { if (depthBuffer[index] < z) { return; // Discard } depthBuffer[index] = z; backBuffer[index4] = (byte)(color.Blue * 255); backBuffer[index4 + 1] = (byte)(color.Green * 255); backBuffer[index4 + 2] = (byte)(color.Red * 255); backBuffer[index4 + 3] = (byte)(color.Alpha * 255); }
Using with this second approach, I’m moving from an average of 45 FPS to 53 FPS. You may think that the performance boost is not that impressive. But in the next tutorial, the drawTriangle method will be much more complex to handle shadows & lighting. For instance, using this approach with the Gouraud Shading, parallelization will almost double the performance.
We can also analyze the new Cores view with this second parallelization approach:
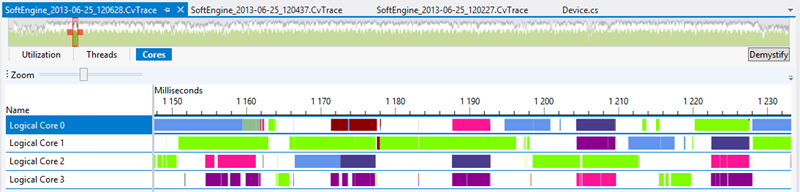
Compare it to the previous Cores view and you’ll see why this is much more efficient.
You can download the C# solution containing this optimized version here:
– C# : SoftEngineCSharpPart4Bonus.zip
So, what’s wrong with HTML5/JavaScript in this case?
HTML5 offers a new API for JavaScript developers to handle similar approaches. It’s named Web Workers and it can address multi-cores usage in specific scenarios.
David Catuhe & I have already covered this topic several times in these 3 articles:
– Introduction to the HTML5 Web Workers: the JavaScript multithreading approach : you should first read this article if you don’t know Web Workers yet
– Using Web Workers to improve performance of image manipulation : a very interesting article where we’re gaining performance with workers on pixels manipulations
– Tutorial Series: using WinJS & WinRT to build a fun HTML5 Camera Application for Windows 8 (4/4) : the fourth part of a tutorials series where I’m using web workers to apply some filters on images taken with the WebCam.
Communications with workers are done via messages. This means that most of the time the data are sent by copy from the UI Thread to the workers. Very few types are sent by reference. If you’re a C++ developer by the way, don’t see that really as a reference. Indeed, with Transferable Objects, the original object is cleared from the caller context (UI Thread) when transfered to the worker. And almost only the ArrayBuffer falls into this category today anyway and we would need to send an ImageData type rather.
But this not our main problem to try to speed up our 3D engine in HTML5. In case of a copy, the data are sent via a memcpy() operation which is very fast. The real problem is when the workers will have finished their processing job. You need to send back the results to the main thread and this UI thread need to iterate through each arrays sent back to rebuild the main pixels arrays. This operation will simply kills any performance gain we could have in the workers unfortunately.
In conclusion, I haven’t find a way to implement a parallelism approach in HTML5 with our 3D software engine. But I may have missed something. If you manage to workaround the current web workers limitations to obtain a significant performance boost, I’m open to suggestions! :)
Next tutorial will talk about flat shading and gouraud shading. Our objects will start to really shine! :)


